
Heb je je SEO op orde, dan is de kans groot dat je website ook in LLM’s gevonden wordt. Maar zorg er wel voor dat deze LLM’s je website goed kunnen crawlen.
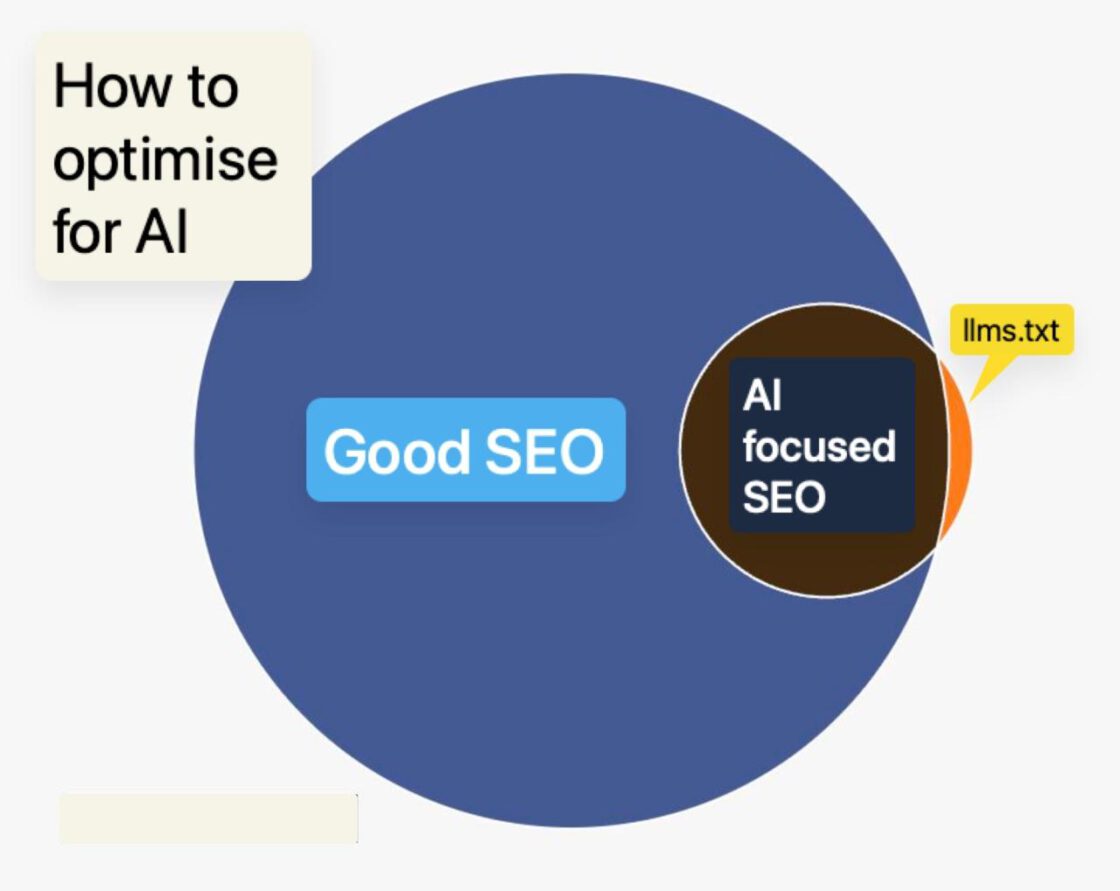
SEO vs. GEO en AEO
SEO was nooit echt makkelijk, maar jarenlang kwam het hier op neer: zorg dat je website technisch in orde is, schrijf goede content en bouw aan je autoriteit (linkbuilding). Als je je website optimaliseert voor echte gebruikers en investeert in je naamsbekendheid, dan zul je je verkeer vanzelf zien stijgen.
Maar in 2025 is het speelveld wel wat veranderd. Naast Google zoeken steeds meer gebruikers via LLM’s (Large Language Models of taalmodellen) zoals ChatGPT, Gemini, Copilot of Perplexity. Dus ook hier wil je vindbaar zijn met je website. Dit wordt GEO (Generative Engine Optimization) of AEO (Answer Engine Optimization) genoemd.
SEO is niet dood
Laten we vooropstellen dat SEO absoluut niet dood is zoals sommigen beweren. Ten eerste zien we in Google Analytics dat nog steeds veruit het meeste verkeer via Google komt. ChatGPT is maar goed voor ongeveer 1% en voor andere LLM’s is dit zelfs nog minder. Ten tweede blijkt uit verschillende rapporten dat Google verkeer zich niet verplaatst naar LLM’s, maar dat de twee elkaar overlappen. In augustus 2025 gold dat 95,3% van de ChatGPT gebruikers ook Google gebruikte, terwijl 14,3% van de Google gebruikers ChatGPT bezocht (bron: Similarweb). Google heeft ook nog altijd 14 x meer bezoekers dan ChatGPT.
Het lijkt erop dat mensen ChatGPT of vergelijkbare platforms vooral gebruiken voor onderzoek, om vervolgens alsnog naar Google te gaan om een specifiek bedrijf te vinden of de juiste webshop om een aankoop te doen. Al kan dit natuurlijk veranderen nu OpenAI heeft aangekondigd dat shopping via ChatGPT in de toekomst mogelijk wordt met Instant Checkout.
Voor webshopeigenaren en marketeers is het belangrijk je niet te verliezen in deze nieuwe trend, maar je vooral te blijven richten op dat wat altijd al belangrijk was: goede content en een fijne gebruikerservaring op je website waarmee je je bezoekers op weg helpt.
Bovendien geldt dat goede SEO ook de basis is van vindbaarheid in LLM’s, dus daarmee sla je twee vliegen in één klap.
Echter is er één belangrijk punt als het gaat om vindbaarheid in LLM’s waar maar weinig over gesproken wordt en dat is crawling van je website.
Hoe LLM’s je website crawlen
Waar AI tools als ChatGPT, Gemini of Copilot hun informatie vandaan halen, verschilt per toepassing. Een deel komt uit trainingsdata: gigantische datasets die tijdens het ontwikkelen van het model zijn verzameld. Deze data is vaak 6 tot 24 maanden oud (bron: ChatGPT). Content die je recent pas online hebt gezet zit hier dus niet in.
Een groeiend deel komt daarnaast uit real-time webcrawling: AI’s die tijdens het beantwoorden van een vraag live op het web browsen om actuele informatie op te halen, te citeren of samen te vatten. Real-time is overigens ook relatief: LLM’s maken meestal gebruik van gecachte pagina’s of snippets op basis van wat eerder gecrawld is. De actualiteit van die data hangt dus af van hoe vaak een site opnieuw wordt gecrawld. In de praktijk betekent dit dat ‘real-time’ data:
- soms écht live is
- soms een paar uur tot dagen oud is bij grote, actieve sites;
- maar bij kleinere of minder vaak bezochte pagina’s ook weken tot maanden oud kan zijn.
Voor real-time antwoorden (RAG) is het goed om te weten dat elk model op zijn eigen manier zoekt op het web:
- Copilot gebruikt Bing Search-API.
- Gemini gebruikt Google Search.
- ChatGPT (alleen in de Pro-versie met browsing ingeschakeld) gebruikt de eigen crawler ChatGPT-User, vaak via Bing als tussenlaag.
- Claude gebruikt de crawler ClaudeBot voor het ophalen van actuele informatie, afhankelijk van de configuratie.
- Perplexity gebruikt zijn eigen crawlers zoals PerplexityBot.
Dit betekent dat jouw website niet alleen interessant moet zijn voor zoekmachines, maar óók toegankelijk moet zijn voor deze nieuwe generatie crawlers. Want als jouw site niet bereikt kan worden door de juiste bots, word je simpelweg niet meegenomen in de antwoorden die AI-gebruikers te zien krijgen. Geen vermelding betekent geen zichtbaarheid, geen link en geen verkeer op je website via LLM’s.
En dat gebeurt sneller dan je denkt. Veel websites maken (bewust of onbewust) gebruik van systemen zoals Cloudflare, die LLM bots standaard blokkeren om serverbelasting of misbruik te voorkomen. Daardoor kan een LLM je content niet crawlen en bereiken, zelfs niet als die perfect aansluit bij de vraag van de gebruiker. Ook IT-beheerders of hostingpartijen blokkeren deze bots soms, bijvoorbeeld als de server de vele requests niet aan kan.
Wat is Cloudflare en waarom doet het ertoe?
Cloudflare is ooit begonnen als CDN (Content Delivery Network), maar is inmiddels uitgegroeid tot een enorme infrastructuurspeler die 20% van het wereldwijde webverkeer afhandelt. Ze bieden onder andere DDoS-bescherming, caching, firewall-instellingen en geavanceerde botmanagement. Veel hostingproviders gebruiken Cloudflare standaard en ook veel webshops maken gebruik van Cloudflare.
Maar sinds juli 2025 blokkeert Cloudflare standaard alle AI crawlers, van OpenAI’s GPTBot tot PerplexityBot. Zonder expliciete toestemming kunnen deze bots je website dus niet meer crawlen. Resultaat: geen vermelding in ChatGPT of andere AI tools, tenzij je handmatig uitzonderingen maakt of tenzij je content al in de trainingsdata zat.
Hoe groot dit probleem is hangt af van jouw website, je doelstellingen en wat LLM’s betekenen voor jouw organisatie.
Denk bijvoorbeeld aan contentpublishers. Voor hun zit het verdienmodel in de content zelf. Denk aan advertentie-inkomsten of betaalmuren. Als AI bots al die content gratis gebruiken en vermelden zonder daar iets (verkeer) voor terug te geven, blijft er niets over om op te verdienen. Het is met name voor deze organisaties dat Cloudflare heeft besloten AI bots standaard te blokkeren en een ‘pay-per-crawl’ wil introduceren, waarbij een website vergoed wordt als LLM’s de site crawlen.
Voor e-commerce websites en veel andere dienstverleners ligt dit anders. Die willen vooral zichtbaar zijn in productvermeldingen of aanbevelingen. Als een AI model producten aanbeveelt en de gebruiker kan doorklikken naar de website om deze te bestellen is dat natuurlijk mooi. Deze websites willen dus juist zichtbaar zijn in LLM’s.
Gebruik je Cloudflare of worden AI bots op serverniveau geblokkeerd, dan betekent dit concreet:
- Voor trainingsdata: je nieuwe content komt niet in toekomstige modelversies van ChatGPT of andere LLM’s terecht.
- Voor real-time antwoorden (RAG): als je de crawlers of user-agents blokkeert waarmee LLM’s browsen op het web kan de LLM jouw site niet raadplegen voor actuele vragen of citaten.
In beide gevallen geldt: als jouw site niet toegankelijk is voor deze bots, mis je zichtbaarheid.
Het dilemma: zichtbaar zijn versus controle houden
Voor website-eigenaren, IT-beheerders en SEO-specialisten ontstaat er een lastig dilemma: je wilt dat AI tools je content gebruiken, zodat je wordt genoemd of gelinkt in antwoorden, maar je wilt niet dat je hele site klakkeloos wordt gekopieerd, zonder credits of verkeer. En je kunt niet al het botverkeer toelaten, want sommige crawlers misdragen zich en zorgen voor een hoge serverload (waardoor je website traag of zelfs onbereikbaar kan worden).
Cloudflare biedt hiervoor dus een aantal oplossingen, zoals een verified bot-systeem en een configuratie-instelling om AI bots toe te staan, maar deze optie staat standaard uit. Daardoor blokkeren veel sites al het verkeer van LLM’s, zonder dat websitebeheerders of marketeers het doorhebben.
Crawl-to-referral ratio
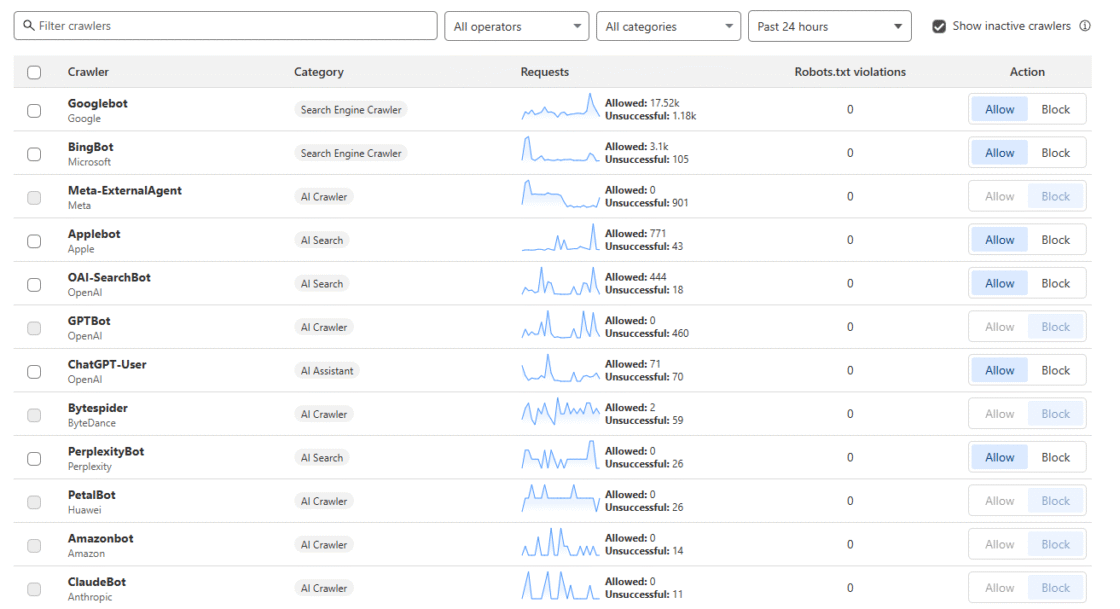
De kern van het probleem zit in de verhouding tussen hoeveel een bot crawlt en wat dat oplevert. Googlebot bijvoorbeeld crawlt veel, maar stuurt ook veel bezoekers terug naar je site. Hier geldt: hoe beter je content, hoe hoger je rankt, hoe meer verkeer je krijgt. Een gezonde verhouding.
Bij AI crawlers is de verhouding vaak helemaal uit balans. Uit analyses blijkt dat bots zoals GPTBot of PerplexityBot soms duizenden keren een site bezoeken zonder ook maar één bezoeker terug te sturen. OpenAI’s crawl-to-referral ratio is geschat op 1.700:1. Bij Anthropic (Claude) liep dat zelfs op tot 73.000:1.
In andere woorden: ze scrapen je content, hergebruiken en vermelden die misschien zelfs, maar je krijgt er niets voor terug. Voor veel uitgevers is dat onacceptabel. Vandaar de oproep om crawlers te laten betalen, of op z’n minst gecontroleerd toegang te geven.
In het geval van Perplexity ging het zelfs een stap verder. PerplexityBot zou volgens Cloudflare ook gebruikmaken van IP-rotatie, user-agent spoofing en het negeren vanrobots.txt, oftewel doen alsof ze een gewone browser zijn om blokkades te omzeilen. Cloudflare blokkeert daarom PerplexityBot nu volledig. Maar dat laat wel zien hoe ingewikkeld dit is. Dit moet per bot bekeken worden. Er is geen kant-en-klare oplossing.
En dan zijn er nog de hostingproviders…
Cloudflare is niet de enige die AI bots blokkeert. Er zijn ook hostingproviders die AI bots standaard blokkeren. Een voorbeeld hiervan is Savvii, o.a. gespecialiseerd in Magento hosting. Savvii geeft aan dat ze gebruikmaken van Fail2ban om ongewenst verkeer te voorkomen. Eén van de filters die ze gebruiken is de Apache-bad-bots filter. Dit is een open source project en bevat een lijst met veelvoorkomende bots die als ongewenst bekend staan, waaronder GPTBot. Is je website gehost bij Savvii, dan zal dit betekenen dat veel LLM bots standaard geblokkeerd worden.
Waarschijnlijk zijn er veel meer hostingpartijen die standaard gebruikmaken van botfilters of andere bescherming. Veel website-eigenaren en online marketeers zijn hiervan niet op de hoogte. Wil je dit controleren of een blokkade opheffen? Neem dan contact op met je hostingprovider.
We hebben bij enkele hostingproviders nagevraagd hoe dit bij hun geregeld is. Hypernode laat weten: “In theorie doen wij niks qua omgaan met bots, maar maken wij het wel inzichtelijk welke bots en in welke hoeveelheid er verzoeken worden gedaan. Op het moment dat wij zien dat een server wordt overbelast door een server, blokkeren wij deze wel en sturen wij een mail naar de klant.” Ook kunnen klanten dit zelf beheren via de Bot Blocklist in het control panel.
Hostnet wil niet reageren op deze vraag.
Wat kun je doen als SEO-specialist?
Allereerst is het belangrijk om te weten wat je wilt en dit te overleggen met andere betrokkenen. Wil je dat LLM’s je website juist wel of niet mogen crawlen? Heb je een besluit genomen, controleer dan de volgende punten.
- Controleer of je site AI bots blokkeert
Check je robots.txt én je hostingconfiguratie of Cloudflare instellingen of vraag dit na bij je websitebeheerder. Bij twijfel kun je logbestanden analyseren (logfile analyse is anno 2025 belangrijker dan ooit). - Pas je robots.txt aan indien nodig
- Configureer Cloudflare naar jouw wensenGa naar Security – Settings en controleer of “AI Scrapers & Crawlers” aanstaat. Gebruik firewall rules om gewenste bots toe te laten en andere te blokkeren. Via AI Crawl Control kun je per bot kiezen of je deze aan of uit wil zetten.
- Stem af met je hostingpartij
Vraag na of er botfilters actief zijn (zoals Apache-bad-bots, Fail2ban). Vraag om een uitzondering op specifieke bots als je dit wilt, of laat je developer dit instellen.
Kies je voor zichtbaarheid in ChatGPT en andere LLM’s? Besteed dan veel aandacht aan unieke content en zorg voor een goede structuur (headings, structured data). Denk ook aan een actuele sitemap en productfeed.
Veel succes!
