Wat betekent duplicate content?
Duplicate content betekent letterlijk: een identiek tweede exemplaar van je content. Er zijn twee vormen van duplicate content:
- een stuk tekst dat op verschillende pagina’s te vinden is. Bijvoorbeeld een blogartikel dat op twee verschillende websites staat;
- één pagina die door middel van verschillende url’s te bereiken is. Het bekendste voorbeeld is je website die op www.website.nl staat en ook te bereiken is via website.nl (zonder www).
Waarom is duplicate content slecht voor SEO?
Duplicate content is slecht voor SEO omdat Google graag unieke zoekresultaten wil presenteren, zodat gebruikers van de zoekmachine verschillende unieke resultaten te zien krijgen na een zoekopdracht. Dat bevordert de kwaliteit van de zoekmachine. Stel je bent op zoek naar een recept voor een appeltaart. Dan zie je liever 10 verschillende recepten op pagina 1 van Google zodat je daar uit kunt kiezen, dan dat je steeds een kopie van het eerste recept ziet.
Als er dus meerdere exemplaren van jouw content of jouw pagina bestaan, dan zal Google er hoogstens één van kiezen om in de zoekresultatenpagina op te nemen. Eigenlijk concurreren de twee varianten dan met elkaar. En de kans dat één ervan wint van een site die dit wel op orde heeft is niet zo groot.
Levert duplicate content een penalty op?
Er wordt weleens gezegd dat duplicate content wordt afgestraft door Google. Dat is eigenlijk niet helemaal juist. Je zult er nooit een penalty voor krijgen.
Wanneer de duplicate content op verschillende websites staat, zal Google proberen te achterhalen welke content het eerst bestond. Deze wordt dan als het origineel aangemerkt en zal waarschijnlijk goed vindbaar zijn in Google. De kopie zal niet of op een lagere positie getoond worden.
Gaat het om één pagina die via meerdere url’s te bereiken is en is in de code niet aangegeven welke als origineel beschouwd moet worden, dan bepaalt Google dat zelf. Dat kan negatief uitpakken.
Hoe weet ik of mijn website duplicate content bevat?
Er zijn een aantal manieren om te controleren of je website een duplicate content probleem heeft. Ook dit is afhankelijk van het soort duplicate content:
Dezelfde content op verschillende websites
Het is natuurlijk moeilijk om te ontdekken of jouw teksten door iemand anders zijn gekopieerd, maar Copyscape kan je hierbij helpen. Vul de url in waar de content op staat, en Copyscape herkent of teksten ergens anders op het web te vinden zijn.
Dezelfde content op verschillende pagina’s binnen je eigen website
In dit geval kun je onderscheid maken tussen duplicate content en common content. Duplicate content betreft hele alinea’s die exact hetzelfde zijn. Common content betreft woorden en andere items die op (vrijwel) al je pagina’s terugkomen. Denk aan je menu en je footer.
Hoewel common content gebruikelijk is en daardoor niet zo’n probleem voor SEO, is het wel slim om te controleren of het echt gaat om dat soort algemene blokken. Stel dat je bijvoorbeeld een ‘over ons’ tekst van meerdere zinnen in je alinea hebt staan, dan wordt de scheidslijn tussen common content en duplicate content heel dun.
Wij gebruiken Siteliner om websites te checken op interne duplicate content en common content.
Eén pagina die via meerdere url’s te bereiken is
Dit type duplicate content is wat technischer en vaak lastig zelf op te lossen. Hier volgen nog een aantal voorbeelden om aan te geven wanneer dit soort duplicate content voor kan komen.
- www versus niet-www. Dit voorbeeld noemden we al eerder. Veel websites beginnen met www, maar dit hoeft niet. Het maakt voor SEO niet uit welke van de twee opties je kiest, maar je moet wel zorgen dat je site maar op één van de twee opties bereikbaar is. Google ziet ze anders namelijk als twee aparte sites en dus als duplicate content
- http versus https. Dit komt op hetzelfde neer als www en niet www. Vroeger begonnen alle websites met http://. Later kwam daar de variant https:// bij. Daaraan kun je herkennen dat een website een SSL-certificaat heeft en dus via en beveiligde verbinding loopt. Google geeft de voorkeur aan websites met een SSL-certificaat, vandaar dat tegenwoordig bijna alle websites beginnen met https://. Echter: is je website op beide variante bereikbaar, dan is dit ook een geval van duplicate content.
- Url’s met parameters. Stel je hebt een webshop met daarin een categorie schoenen. Je url is dan bijvoorbeeld www.website.nl/schoenen. Stel dat je op die pagina kunt filteren op schoenmaat, dan wordt er meestal een aangepaste url gecreëerd, bijvoorbeeld www.website.nl/schoenen?schoenmaat=39. Op de pagina krijg je misschien wat minder verschillende schoenen te zien, maar verder is de pagina exact hetzelfde gebleven.
Dit zijn een aantal gevallen die vaak voorkomen, maar er zijn nog veel meer situaties die duplicate content veroorzaken. Gelukkig zijn ze eenvoudig op te sporen met SEO software. Wij gebruiken hier Screaming Frog voor, maar vrijwel alle bekende SEO tools kunnen dit opsporen.
Dubbele pagina’s achterhalen door middel van Search Console
Ook Google Search Console geeft je veel interessante data waarmee je duplicate content kunt opsporen. Hier kun je het bijvoorbeeld zien als bepaalde pagina’s niet door Google geïndexeerd worden omdat ze als kopie van een andere pagina zijn aangemerkt (‘alternatieve pagina met correcte canonieke tag’) of als er een dubbele pagina is gevonden zonder dat er aangegeven is wat het origineel is (‘dubbele pagina zonder door de gebruiker geselecteerde canonieke versie’). Google kan zelfs aangeven als ze een andere canonieke pagina hebben geselecteerd dan jijzelf. Hoewel dat erg vervelend is, is daar niet altijd iets aan te doen.
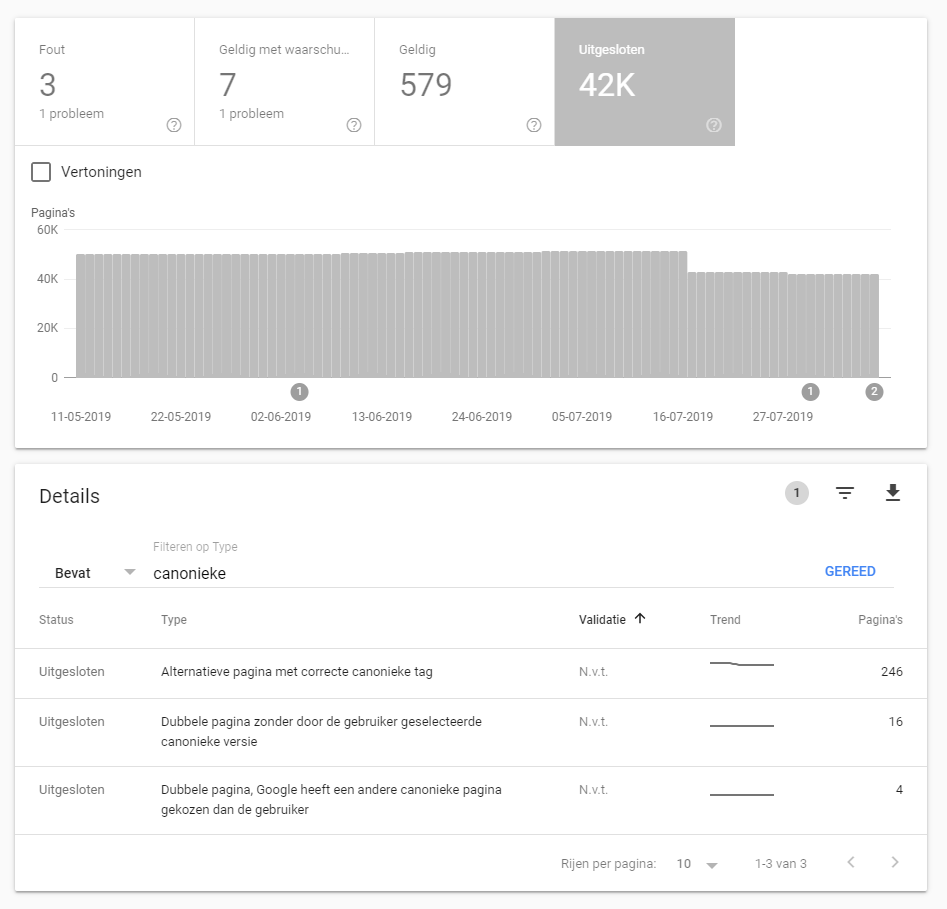
Als je op één van deze meldingen klikt kun je voorbeelden van url’s zien waar dit probleem speelt. Als je vervolgens een voorbeeld-url inspecteert in Search Console kun je zien welke URL Google heeft aangemerkt als origineel (‘Door Google geselecteerde canonieke URL’).
Hoe los je duplicate content op?
Zit het probleem hem in gekopieerde teksten, dan kun je deze natuurlijk zelf herschrijven zodat ze uniek zijn voor al je pagina’s. Heeft iemand je teksten gekopieerd? Neem dan contact op met het verzoek de teksten aan te passen.
In het geval van pagina’s die via meerdere url’s te bereiken zijn moet je ervoor zorgen dat dit niet meer het geval is. Dit doe je meestal door middel van een 301 redirect. Hiermee zeg je tegen Google dat één url niet meer actief is en naar welke url een bezoeker doorgestuurd moet worden. In het geval van het www versus niet www voorbeeld kies je één van de twee varianten, en zorg je dat de andere variant wordt geredirect naar de eerste.
Is dit niet mogelijk (zoals in het voorbeeld met de filters), dan moet je Google laten weten dat er meerdere varianten van een pagina zijn. In dat geval kun je in de broncode aangeven welke van de varianten als origineel aangemerkt moet worden en welke duplicaten zijn. Dit doe je met de canonical tag die je in de <head> van broncode plaatst.
Een canonical tag (door Google ‘canonieke url’ genoemd) ziet er als volgt uit:
<link rel=”canonical” href=”https://www.webdesigntilburg.nl/” />
Je geeft hiermee aan dat dit het origineel is. Als Google deze canonical op een andere url tegenkomt, weet Google dat hij die andere url niet moet indexeren en zal hij alleen het origineel indexeren.


Hulp nodig met SEO
